
1. Introduction
Cette exploration de l’évolution terminologique des sciences de l’information s’inscrit dans le cadre d’une étude plus large qui vise à caractériser une langue, l’anglais, dans un domaine spécialisé particulier, les sciences et les métiers de l’information. Lorsque l’on observe le corpus relativement considérable des travaux en anglais de spécialité en France comme à l’international, il apparaît rapidement que l’anglais des sciences et des métiers de l’information est un domaine de la connaissance largement méconnu des anglicistes de spécialité. Les travaux portant plus particulièrement sur l’anglais utilisé par les professionnels de l’information, qu’il s’agisse des bibliothécaires, des documentalistes, des archivistes, et autres records managers sont quasi-inexistants. La seule étude identifiable dans ce domaine est sans doute celle de Georges Fournier qui, en 2012, consacre un article entier à Dan Starer qui exerçait le métier de documentaliste indépendant pour les écrivains américains à la recherche d’informations attestées (Fournier 2012). En dehors de ce cas très spécifique, aucune étude n’aborde vraiment la question de l’anglais utilisé dans le domaine de l’information.
Pourtant, les métiers de l’Information et les différentes sciences qu’ils mobilisent ont connu une évolution fulgurante depuis la fin du XIX° siècle, un moment de l’histoire souvent qualifié par les historiens du domaine « d’explosion documentaire ». À cette période en effet, la forte augmentation de la production scientifique et de la documentation professionnelle s’accompagne d’un développement des méthodes de classification, à la fois dans le monde anglophone et dans le monde francophone. En 1876, Melvil Dewey publie une classification décimale encore en usage aujourd’hui et connue sous l’acronyme DDC (Dewey Decimal Classification). Quelques décennies plus tard, en 1934, Paul Otlet, généralement considéré comme le père de la documentation, publie son Traité de Documentation qui, selon Leroux et al., « préfigure, dans une certaine mesure, l’invention d’internet un demi-siècle à l’avance » (2010 : 18). C’est également au tournant du XXe siècle que naissent les premières grandes institutions et sociétés savantes du domaine comme l’American Library Association (1876), la Library Association de Londres (1877) et la School of Library Economics (1887, université de Columbia à New York), l’Association of Special Libraries and Information Bureaux (1924) qui deviendra par la suite l’Association for Information Management et l’International Federation for Information and Documentation fondée en 1895 par Paul Otlet. Depuis cette période, la notion d’information n’a cessé d’évoluer. À la fin des années 1940, elle est encore largement centrée sur la matérialité du document mais le développement de l’informatique, dès les années 1950, bouleverse les techniques de recherche d’information pour l’entraîner vers l’immatérialité du big data et autres clouds.
Au cours de cette histoire, que nous résumons très brièvement, de nouveaux concepts et par là-même de nouveaux termes, sont apparus et forment aujourd’hui un univers conceptuel particulièrement riche. Au-delà des cas célèbres décrivant l’immatérialité de l’information, l’expansion terminologique couvre un ensemble relativement hétéroclite de branches de la connaissance allant des sciences des bibliothèques à la gestion des connaissances en entreprise en passant par la gestion des archives. Les sciences de l’information sont, à l’évidence, multiples et une question se pose concernant la possibilité de les envisager comme un domaine spécialisé à part entière, c’est-à-dire un domaine observable du point de vue d’une langue de spécialité. La question revêt d’autant plus d’importance que pour les anglicistes de l’enseignement supérieur ou des filières telles que les D.U.T Info-Com, les licences et les masters en sciences de l’information et de la documentation ou encore l’École nationale supérieure des sciences de l’information et des bibliothèques, intègrent depuis longtemps des formations en anglais. Ces formations auraient tout à gagner d’une meilleure connaissance de cette langue de spécialité dont nous tentons ici d’esquisser quelques contours.
L’étude qui suit est une première exploration de l’évolution terminologique des sciences de l’information entre 1945 et 2015. Nous commençons par conceptualiser ces sciences en domaine spécialisé, observable du point de vue de l’anglistique de spécialité. Nous poursuivons en présentant un corpus diachronique en sciences de l’information conçu pour l’observation de l’évolution terminologique. Nos résultats montrent qu’au-delà du caractère spectaculaire de l’évolution, liée à l’abondance des nouveaux termes, des phénomènes plus profonds, d’ordre sémantique, sont à l’œuvre. Il s’avère en effet qu’en dépit du maintien du terme, le concept d’information a profondément changé depuis 1945.
2. Cadre théorique
2.1 Sciences et métiers de l’Information : L’hypothèse d’un nouveau domaine spécialisé
Il est possible de concevoir l’Information1 comme un domaine spécialisé à part entière, c’est-à-dire comme un objet observable et légitime du point de vue de l’anglistique de spécialité. À l’instar d’autres domaines tels que l’économie, la finance, le droit ou la médecine, l’Information présente les caractéristiques centrales des domaines spécialisés tels que Van der Yeught (2016) les envisage, c’est-à-dire des concepts ou des ensembles de concepts qui traversent le temps et les communautés spécialisées et dont les origines se trouvent chez des individus particuliers, animés d’une intention particulière :
Dans les domaines spécialisés, les croyances et les désirs d’individus particuliers se métamorphosent en buts abstraits, lesquels buts transcendent les communautés spécialisées déterminées par le temps et l’espace qui les ont produites. Le but ultime du domaine spécialisé de la médecine est de soigner les malades et de préserver la santé, qu’il s’agisse de la médecine pratiquée en Grèce antique, en Chine traditionnelle, à l’époque de la Renaissance en Europe ou de l’Amérique moderne. (Van der Yeught 2016 : 50)2
Les historiens des sciences de l’Information tels que William Aspray, Boyd Rayward ou Michael Buckland nous permettent de retracer l’Information dans ses origines singulières, notamment le fait qu’elle soit issue de l’intention de quelques pionniers considérés aujourd’hui comme les figures de proue du domaine, en particulier Jason Farradane, Vennevar Bush, Paul Otlet et Gerald Salton. Leur histoire nous permet également d’observer que l’Information a largement dépassé la communauté relativement restreinte des bibliothécaires pour atteindre d’autres sphères professionnelles (des archivistes aux « courtiers en connaissances » en passant par les records managers) et scientifiques (étude des systèmes d’information, travaux sur la recherche d’information, la netométrie, la cybermétrie, etc.) et, au fond, la société dans son ensemble à travers le concept de « société de l’information ».
Outre une histoire partagée d’où émergent certaines grandes figures du domaine, les sciences de l’Information présentent une autre caractéristique des domaines spécialisés, celle de l’existence d’un savoir encyclopédique et, par là-même, d’une terminologie acceptée par les membres des communautés qu’elle représente. Ce savoir est véhiculé par de nombreuses sociétés professionnelles telles que l’International Federation of Library Associations pour les bibliothécaires, la Society of American Archivists pour les archivistes, l’Association for Information and Image Management pour les records managers, ou encore l’Association for Information Science & Technology pour les chercheurs. En outre, la plupart de ces organisations possèdent leurs propres organes de diffusion, qu’il s’agisse de revues de recherche universitaire (International Journal of Information Science and Technology, Records Management Journal, Journal of Documentation), de revues à orientation plus professionnelle (The American Archivist, Journal of Information Management, Journal of Enterprise Information Management) ou des magazines de vulgarisation (Wired, Information Management Magazine, Document Strategy). Elles possèdent également un ensemble relativement important de normes portées par des organismes nationaux (Afnor pour la France, ISO pour l’international, CEN pour l’Europe) ou par l’International Federation of Library Association. Ces institutions définissent les bonnes pratiques liées à la gestion informationnelle et documentaire comme la norme ISO 15489 qui porte sur la gestion des documents d’activités ou records management.
Une autre caractéristique qui pourrait faire de l’Information un domaine spécialisé légitime est le fait que la communauté s’est dotée d’institutions de formations, héritières des écoles de bibliothécaires, dont la première dans le monde anglophone fut fondée en 1877 par Melvil Dewey, au sein de l’université de Columbia aux États-Unis. Depuis cette date, des programmes d’études spécifiques se sont développés dans le cadre de Bachelors ou de Masters en sciences ou en gestion de l’Information. Certaines organisations telles que l’Association for Information and Image Management, proposent également des formations tout au long de la vie permettant aux professionnels du domaine d’obtenir une certification comme la certification CIP (Certified Information Professional).
2.2. Histoire des domaines spécialisés et approches diachroniques de l’anglais de spécialité
L’approche historique des domaines spécialisés forme un aspect désormais relativement incontournable pour l’étude des langues de spécialités : l’éclairage porté sur un domaine particulier permet de mieux saisir les usages dont certains sont particulièrement opaques en l’absence de regard historique. Il faut par exemple étudier l’histoire des sciences de l’Information et celle de la formation des différents corps de métiers pour comprendre que le documentation anglophone tire son substrat théorique de courants issus des library studies, contrairement au monde francophone où la notion de documentation bénéficia très tôt d’une forte conceptualisation notamment grâce au Belge Paul Otlet. Il n’y a donc rien d’étonnant à ce que le documentaliste anglophone ne se considère pas vraiment comme un documentalist mais plutôt comme un special librarian, un specialised librarian ou encore un scientific librarian, le terme documentalist étant utilisé de manière tout à fait marginale, généralement dans des cas très spécifiques, comme les documentalistes indépendants (Fournier 2012).
Outre le caractère éclairant de l’approche historique pour rendre compte des usages de la langue à l’intérieur des domaines spécialisés (Van der Yeught 2009), les études diachroniques de l’anglais de spécialité permettent d’éclairer le domaine dans son ensemble (Banks 2011). Ce type d’études a fait l’objet d’une revue récente et approfondie par Banks (2016) pour qui l’essentiel des travaux porte sur le discours scientifique (Salager-Meyer 1999), qu’il s’agisse du discours médical (Dury 2005, Rowley-Jolivet, 2010), du discours de la biologie (Magnet 2001) ou de celui de la géologie (Château 2010). Parmi les genres de discours étudiés d’un point de vue diachronique, l’article scientifique occupe une place prépondérante. Son archivage, dès son apparition dans les premières Philosophical Transactions que Banks a très largement analysées, a rendu possible l’observation des textes à l’échelle de plusieurs siècles sous des angles relativement divers, qu’il s’agisse de l’approche sociolinguistique (étude des textes dans leur situation historique), l’approche discursive (étude des caractéristiques de genre et de registre), l’approche terminologique voire l’approche iconographique à travers la comparaison des images intégrées aux textes scientifiques. Au-delà des textes scientifiques, Banks (2016) observe que les travaux qui portent sur l’étude diachronique d’autres variétés spécialisées sont en réalité assez rares, ces études se concentrant sur les textes religieux (Taavitsainen 1994), la terminologie juridique (Wagner 2003) et le discours de l’alpinisme (Wozniak 2015).
2.3. Les corpus diachroniques en anglais de spécialité
Comme nous venons de le voir, l’approche historique des domaines spécialisés occupe une place de choix dans cette branche de l’anglistique. Mais qu’en est-il des corpus diachroniques spécifiquement conçus pour représenter l’évolution d’une langue de spécialité en tant que telle ? Ce type de représentation est, en réalité, très rare car les corpus spécialisés sont, pour la très grande majorité, conçus comme un échantillonnage synchronique visant à comparer des domaines, des genres ou des registres quelle que soit l’époque. Nous faisons donc ici la différence entre les corpus historiques spécialisés, qui visent la représentation d’une variété spécialisée sur une période donnée, et les corpus diachroniques spécialisés, qui cherchent à représenter l’évolution d’une variété, sur la base d’une structure organisée par période (Gries et Hilpert : 2008).
Comme Dury (2004) le suggère, cette seconde catégorie remplit des fonctions porteuses pour l’étude des variétés spécialisées. Elles nous renseignent tout d’abord sur l’évolution des usages, en particulier les termes, même si la période étudiée est relativement courte :
Les corpus diachroniques, même s’ils couvrent une période relativement courte (…), peuvent fournir des exemples de certains types de structures, certaines façon d’utiliser les termes ou encore apporter un éclairage sur les caractéristiques contextuelles d’une période donnée. (Dury 2004 : 613)3
Les corpus diachroniques spécialisés permettent également d’enrichir les définitions, en nous renseignant sur l’apparition ou la disparition de certaines significations. Ils permettent enfin l’observation de processus terminologiques tels que la terminologisation (l’acquisition du statut de terme pour un mot issus de la langue générale) et la déterminologisation (la perte de ce statut et le passage dans la langue générale).
Les corpus diachroniques spécialisés que nous avons pu identifier relèvent de l’anglais scientifique, qu’il s’agisse du domaine de l’énergie et de l’écologie (Dury 2004), du domaine médical (Dury 2008a, 2008b, 2013) ou du domaine scientifique dans sa pluridisciplinarité (Degaetano-Ortlieb et al. 2012). Ce type de corpus peut être de taille relativement grande comme le corpus SciTex (Degaetano-Ortlieb et al. 2012) qui comprend 34 millions de mots ou de taille plus réduite comme le corpus bilingue anglais/ français CIBLSP (Dury 2004) comprenant 1,5 millions de mots dont 700.000 pour la partie anglaise. Ces deux corpus traitent de périodes issues du XXe siècle échantillonnées à l’échelle de quelques décennies.
L’observation des évolutions peut prendre des orientations radicalement différentes. Pour Dury (2013), l’étude diachronique de l’anglais de l’écologie porte sur le lexique, la terminologie et les figures de style telles que la métonymie, ce qui permet à l’auteur d’identifier les représentations et les paradigmes d’une culture spécialisée émergente. Degaetano-Ortlieb et al. (2012) abordent la diachronie dans le cadre d’une étude quantitative de registres à partir d’ensembles de traits lexico-grammaticaux considérés comme des dimensions, dans la lignée des dimensions de registre que Biber avait conçues pour l’étude de la langue générale (Biber et al. 1998). Ces derniers admettent toutefois que les changements grammaticaux sont moins perceptibles que les changements terminologiques, les premiers étant beaucoup plus lents et diffus que les seconds.
La méthodologie employée pour la constitution de corpus diachroniques spécialisés correspond à celle de tout corpus spécialisé, c’est-à-dire qu’elle repose sur la question de la représentativité et du dosage des différentes parties qui les composent. Dury (2004) attire toutefois notre attention sur des difficultés spécifiques comme le traitement des textes anciens du domaine, parfois peu accessibles et difficiles à numériser en raison de leur état. À ces difficultés s’ajoute le problème de la datation de l’émergence d’un domaine. Cette recherche du point de départ, dont l’étude diachronique des termes rend compte de manière efficace, peut toutefois contribuer à l’épistémologie du domaine en tant que tel.
3. Méthode
3.1. Corpus diachronique d’anglais des sciences de l’Information
Notre étude de l’évolution terminologique en sciences de l’Information se fonde principalement sur un corpus de résumés de recherche issus de deux revues phare du domaine, le Journal of Documentation et le Journal of Information Science. La période couvre 70 ans d’histoire de cette science relativement récente, les premiers résumés datant de 1945, date de la première publication du Journal of Documentation, et les derniers de 2015 (tableau 1). Ce corpus témoigne du changement de paradigme que les scientifiques (et les professionnels) de l’information ont connu depuis la seconde moitié du XXe siècle, que les experts du domaine caractérisent de manière très générale comme le passage d’une information solide, structurée sur un support facilement identifiable (le livre, le périodique, l’image, etc.) à une information fluide, circulant sur les réseaux informatiques et les réseaux sociaux.
Tableau 1. Structure du corpus de résumés d’articles de recherche en sciences de l’information
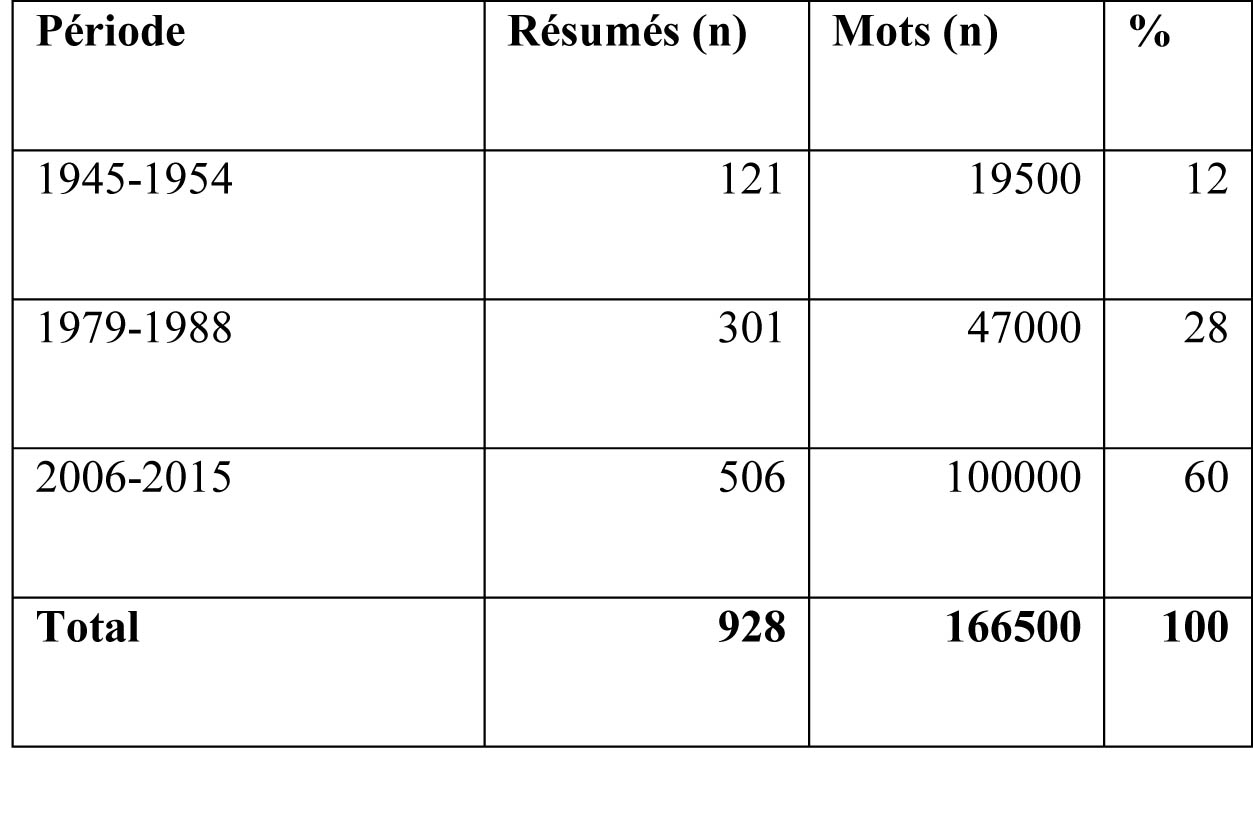
Par sa taille relativement modeste et sa visée précise, notre corpus peut être considéré comme un petit corpus spécialisé. Les 928 résumés qui le composent sont structurés en trois parties, correspondant à trois décennies clés du domaine. La première (1945-1954) correspond à la naissance de la discipline des « sciences de l’information » en tant que telles (Shapiro 1995, Bawden et Robinson 2015) tant dans le monde anglophone que dans le monde francophone. C’est d’ailleurs à cette époque de Guerre Froide que certains grands projets documentaires nationaux voient le jour sous l’impulsion d’institutions dédiées à la recherche scientifique et militaire telles que la célèbre Defense Advanced Research Projects Agency (DARPA) aux États-Unis et l’Office for Scientific and Technical Information (OSTI) en Grande-Bretagne. La deuxième partie (1979-1988) correspond au développement de l’informatique qui ouvre la voie à de nouvelles méthodes de recherche documentaire et conduit à la montée en puissance et la structuration du concept d’Information. C’est à cette époque également que paraît le premier numéro du Journal of Information Science. Enfin, la troisième décennie (2006-2015) vise à représenter la généralisation d’Internet et l’émergence des réseaux sociaux qui apportent de nouveaux bouleversements aux pratiques informationnelles et au concept d’information lui-même.
3.2. Méthode d’analyse
Le domaine étudié étant relativement nouveau au sein des études anglaises, nous nous sommes livrés à un premier défrichage. La méthode retenue pour l’étude du corpus repose principalement sur une approche quantitative à l’aide du logiciel Antconc (Anthony 2011) que nous avons utilisé dans une double perspective, corpus-driven et corpus-based. Dans un premier temps, nous avons utilisé la méthode inductive pour dresser des listes de termes les plus fréquents pour chaque période, l’objectif étant d’identifier les grandes tendances terminologiques, c’est-à-dire les sujets spécialisés les plus récurrents dans chaque période. Toutefois, ce type de liste nous renseigne peu sur la spécificité terminologique d’une période par rapport à une autre. En effet, un terme peut être peu fréquent dans une décennie mais peut être parallèlement spécifique à cette dernière et, par là-même, nous renseigner sur les tendances scientifiques nouvelles. Ce type de trait a été identifié à partir du concept de spécificité lexicale ou keyness (Bondi et Scott 2010) que les listes de mots-clés obtenues grâce au logiciel Antconc permettent de définir. Pour les besoins de cette étude, nous avons opté pour une définition étroite, technique pour ainsi dire, de la notion de mot-clé à partir de la définition de Scott : « Un mot-clé […] est un mot (ou un phrasème) dont la fréquence est inhabituelle dans un texte ou ensemble de textes donnés » (Scott 2010 : 149)4.
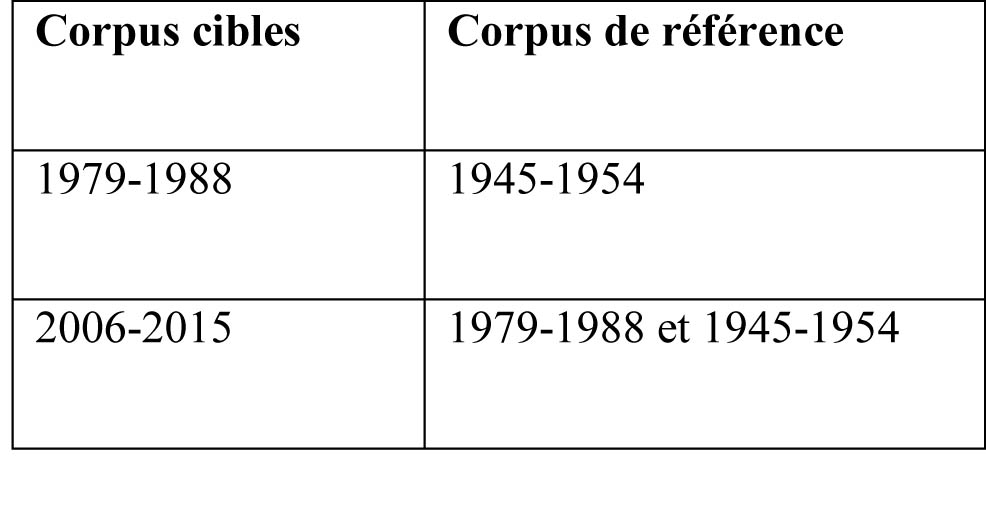
L’obtention de ces listes suppose, d’une part, de définir des sous-corpus cibles, en l’occurrence les deux sous-corpus représentant les deux dernières décennies étudiées, et d’autre part, des corpus de référence, en l’occurrence la ou les décennies précédant la décennie cible. L’identification de la spécificité lexicale propre à chaque décennie est récapitulée dans le tableau 2.
Tableau 2. Corpus cibles et corpus de référence dans l’étude diachronique de la spécificité lexicale (keyness)
Cependant, comme Grabowski (2015) le rappelle dans une étude relativement similaire, la liste générée automatiquement par le logiciel ne saurait être considérée en tant que telle car les items contenus dans les listes n’éclairent pas nécessairement la problématique. Par exemple, les listes de mots-clés pour cette étude présentent un nombre relativement important de mots académiques tels que study, focus, ou encore article dans les décennies 1979-1988 et 2006-2015, ce qui tend à montrer que le discours académique en sciences de l’Information, à l’instar de nombreux autres domaines, s’est normalisé au cours du XXe siècle, notamment en direction du format IMRAD. Dans le cadre de cette étude donc, les listes brutes, générées automatiquement par le logiciel, ont été traitées de manière à ne retenir que les éléments pertinents pour la problématique de cet article, centrée sur l’évolution de la terminologie du domaine des sciences de l’Information. Notre approche quantitative inductive comprend également une étude des acronymes que nous considérons comme des marqueurs de la terminologisation du domaine. Ces marqueurs ont été identifiés au moyen d’un étiquetage systématique de chaque sous-corpus à l’aide de la balise <abbr type="acronym"> issue de la Text Encoding Initiative. Une fois les trois sous-corpus étiquetés, nous avons pu procéder à la comparaison des schémas de fréquence.
L’identification des nouveaux termes (mots, phrasèmes et acronymes) nous a alors permis d’étudier leur comportement phraséologique à partir d’une étude inductive (corpus-based). Pour obtenir ce type d’information, nous avons eu recours au concordancier d’Antconc et, plus particulièrement, aux outils « clusters » et « collocates » qui permettent d’extraire les schémas collocationnels des termes précédemment identifiés.
Enfin, l’approche outillée a été complétée par une approche qualitative, essentiellement centrée sur l’étude des définitions des termes communs aux trois décennies afin d’observer d’éventuelles évolutions sémantiques. Cette partie de l’étude a reposé sur la consultation des différentes éditions d’un même glossaire faisant référence chez les spécialistes du domaine, le Harrods’ Librarians’ Glossary and Reference Book (Harrod 1959, Harrod 1977, Prytherch 1990, Prytherch 1995, Prytherch 2016). Au départ conçu pour le champ relativement restreint de la science des bibliothèques (l’édition de 1959 comprend environ 3000 entrées, centrées sur le livre), son champ d’application a progressivement évolué pour embrasser le champ des sciences de l’information dans son ensemble (la dernière édition, datant de 2016, comprend près de 10200 termes).
3.3. Bilan méthodologique
En résumé, nous avons constitué un petit corpus spécialisé, structuré de telle manière qu’il permet la représentation de l’évolution du domaine des sciences de l’Information depuis 1945. Il convient toutefois de souligner la limite d’un tel échantillon qui représente une période relativement courte à partir de revues en nombre tout aussi limité. Il n’en demeure pas moins que les décennies traitées sont considérées par les experts eux-mêmes comme des périodes cruciales couvrant l’apparition de l’ordinateur et d’internet. Ces phénomènes ont clairement bouleversé les pratiques informationnelles et ont conduit à l’expansion d’un domaine centré, à l’origine, sur le livre imprimé. En outre, le choix des résumés d’articles issus de deux revues phares du domaine nous permet d’obtenir un concentré des tendances scientifiques depuis 1945. À partir de ces éléments, une étude diachronique des sciences de l’Information nous paraît donc envisageable. Nous en présentons les premiers résultats dans la section suivante.
4. Résultats
4.1. Évolution terminologique des sciences de l’information
Notre étude montre que la terminologie de l’Information a connu une très forte expansion tant sur le plan conceptuel, de nouvelles techniques générant de nouvelles significations, que sur le plan formel, l’émergence de nouveaux phénomènes informationnels conduisant à la production de nouvelles formes. Une simple comparaison du nombre d’entrées dans l’un des plus célèbres glossaires anglophones du domaine, le Harrod’s Librarians’ Glossary and Reference Book, permet de voir qu’en l’espace de quelques décennies, le nombre de termes a plus que triplé. À la fin des années 1950, la deuxième édition du glossaire (Harrod 1959) comprenait environ 3000 entrées pour atteindre le chiffre de 10250 dans la dernière édition disponible (Prytherch 2016) dont 1700 sont entièrement nouvelles par rapport à la neuvième édition et près de 3000 ont dû être entièrement révisées pour représenter fidèlement la réalité terminologique du domaine en ce début du XXIe siècle. Cette expansion terminologique repose tout d’abord sur le maintien des activités classiques, fondées sur le livre, qui occupent encore aujourd’hui une place centrale dans les métiers de l’Information. Les professionnels de l’Information ont toujours pour mission principale de classer, de cataloguer et d’archiver les documents, quel que soit le contexte institutionnel (une bibliothèque ou une grande entreprise). Toutefois, la numérisation des activités liées à la recherche d’information a conduit, dès les années 1950 et les débuts de l’ordinateur, à de nouveaux supports (microfiches, disquettes, disques durs, puis les clouds) et de nouvelles méthodes de recherche d’information (de l’index d’ouvrages aux moteurs de recherche sur Internet).
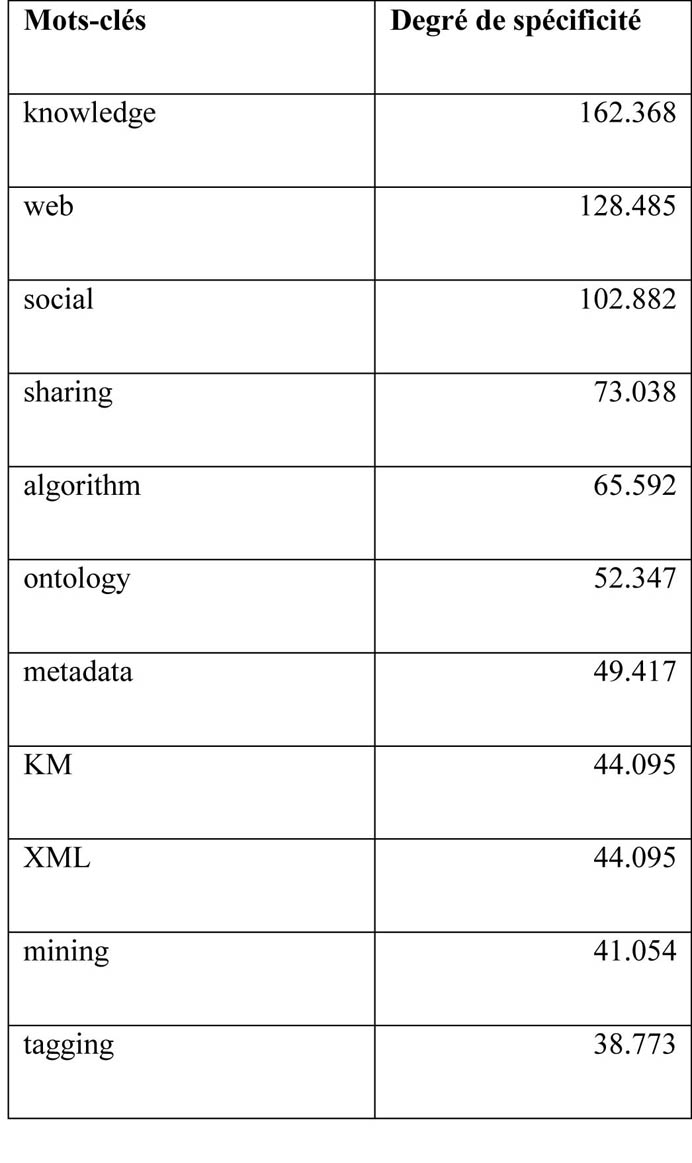
Plus particulièrement, l’analyse du corpus montre que les sciences de l’information ont connu une évolution conceptuelle très marquée : elle reflète nettement l’évolution du contexte dans lequel le domaine s’est développé au cours des trois décennies étudiées. Pendant la décennie 1945-1954 (tableau 3), le domaine est essentiellement centré sur le monde du livre et celui des bibliothèques. Des termes tels que « book », « library » ou encore « bibliography » présentent un fort degré de spécificité par rapport aux autres corpus où ces termes sont bien présents mais ils apparaissent avec un relativement faible degré de fréquence. La recherche d’information, l’un des objets principaux des sciences de l’Information, s’effectue essentiellement par le biais de catalogues, de bibliographies et de microfiches. La situation terminologique des deux décennies suivantes est sensiblement différente (tableaux 4 et 5) : elle témoigne de la révolution conceptuelle du domaine dans laquelle la documentation et ses documents traditionnels, tels que le livre cèdent leur place à l’information et à la donnée (« data ») accessible sur ordinateur. La recherche d’information se complexifie avec l’émergence de nouveaux concepts (« data mining », « tagging », « metadata ») et un nouveau langage documentaire (« XML »), permettant à leur tour le développement de nouveaux concepts tels que le web sémantique. Outre les concepts proprement dits, cette comparaison des mots-clés de chaque décennie illustre un tournant social allant du bibliothécaire comme acteur principal à l’utilisateur lambda (« user ») dont les comportements numériques font désormais l’objet de nouveaux travaux par les chercheurs du domaine.
Tableau 3. Les mots-clés de la décennie 1945-1954
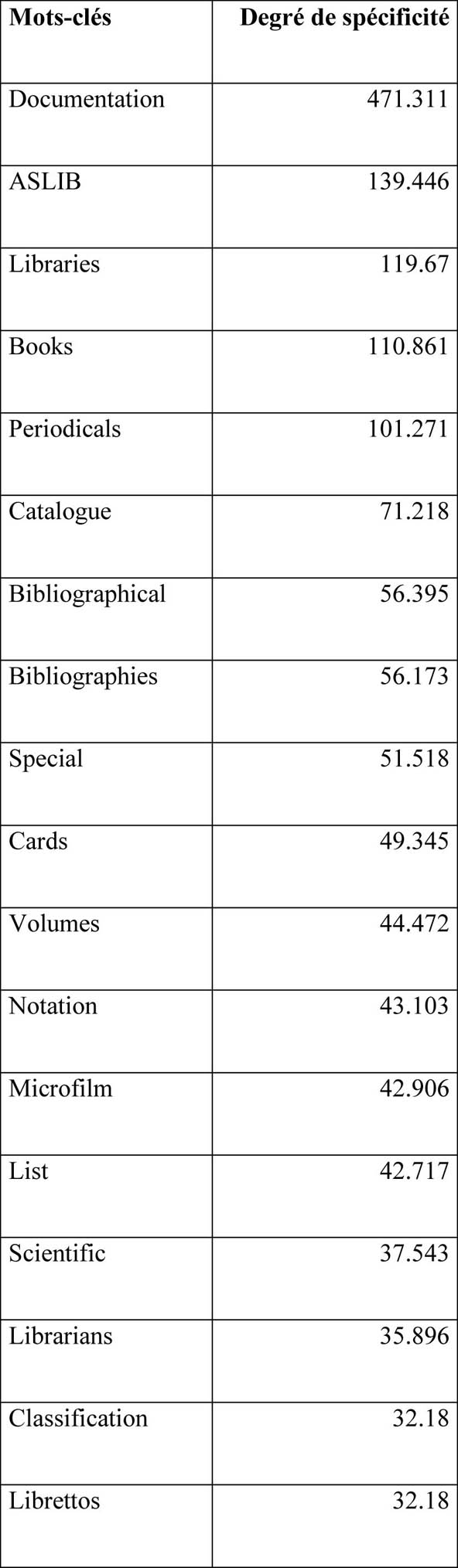
Tableau 4. Les mots-clés de la décennie 1979-1988
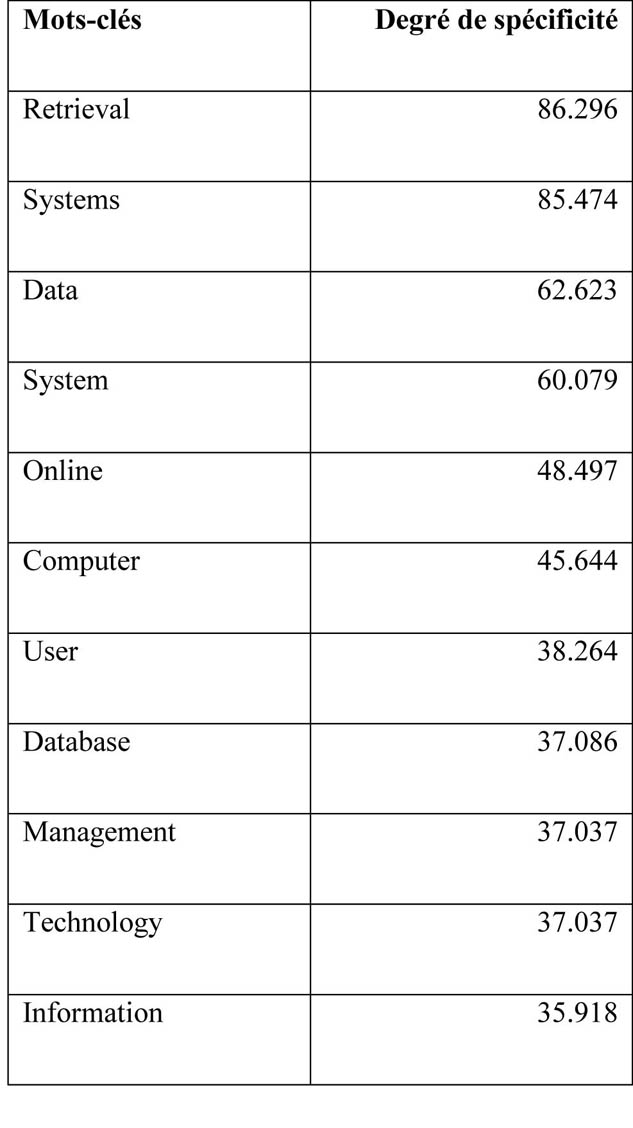
Tableau 5. Les mots-clés de la décennie 2006-2015
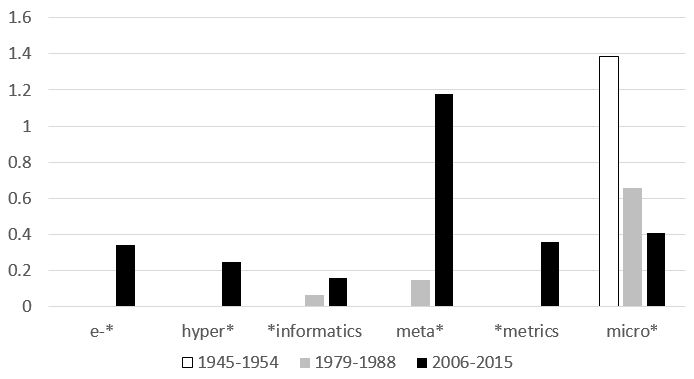
4.2. Évolutions morphologiques : Multiplication des termes-valises et des abréviations
Les termes-valises que nous avons rencontrés au cours de notre analyse s’inscrivent dans la droite lignée des observations précédentes portant sur d’autres domaines spécialisés tels que le commerce en ligne (Humbley 2008) et, plus récemment, l’économie (Resche 2015). Ils consistent en une association de deux termes, éventuellement tronqués, qui constituent alors un nouveau terme employé de manière régulière par les experts du domaine. Comme la figure 1 le montre, la plupart de ces termes apparaissent dans les années 2000 (e-book, hyperlink, bibliometrics). Ils reflètent que les sciences de l’Information sont marquées par le maintien des objets fondamentaux de la discipline (le livre, l’information, les données, etc.) et par l’introduction de nouvelles techniques venant s’appliquer à ces objets (de nouvelles techniques de mesure, de nouveaux formats de données), de nouveaux environnements technologiques (l’ordinateur, le réseau), de nouvelles typologies (data versus metadata).
Figure 1. Préfixes et suffixes formant la base de termes valises en sciences de l’information : Variations de la fréquence entre 1945 et 2015 (par millier de mots)
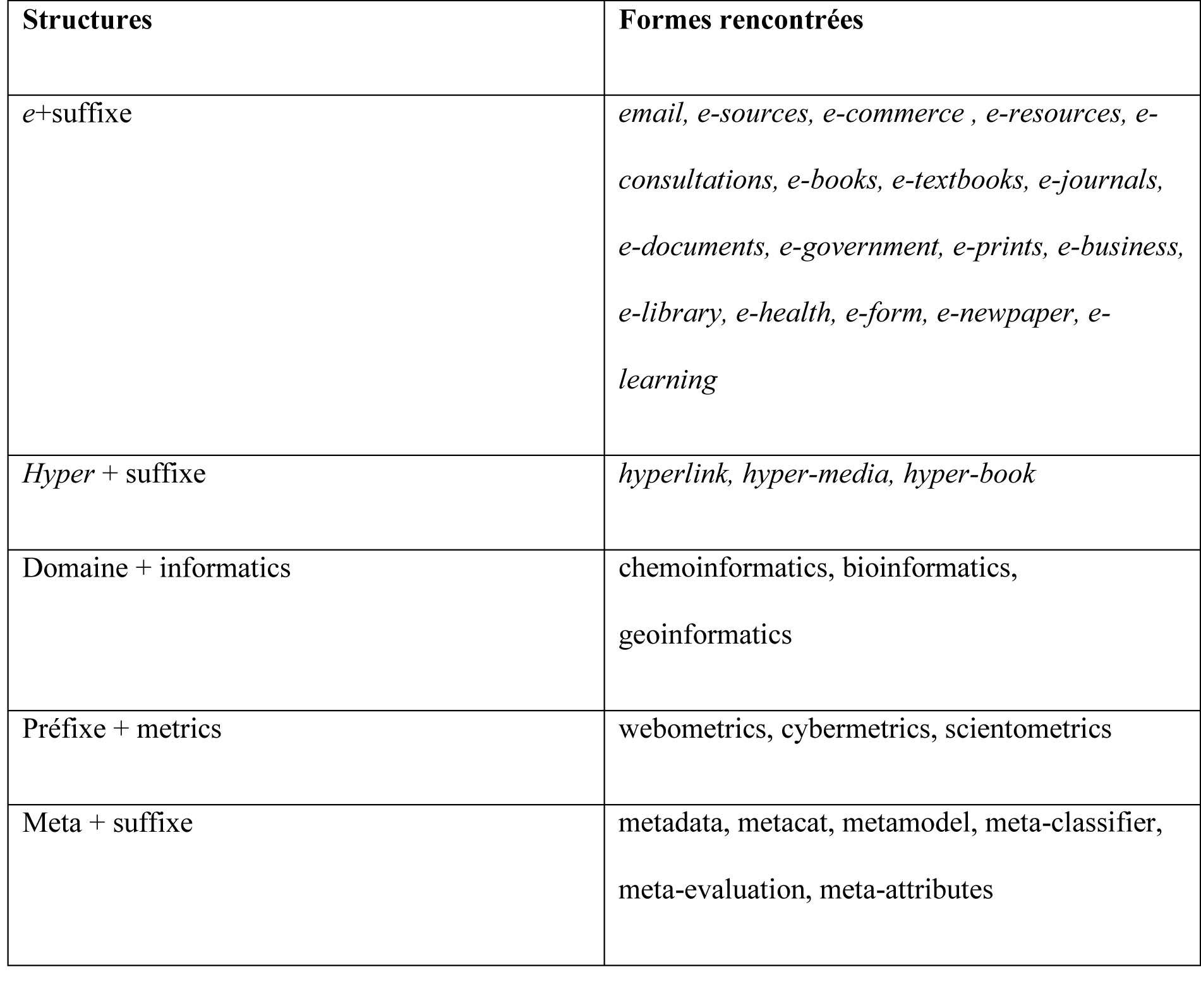
L’analyse des termes-valises permet également de montrer qu’un pan entier des sciences de l’Information concerne le service documentaire aux autres domaines, comme l’illustrent les cas de chemoinformatics5, bioinformatics et geoinformatics. D’autres exemples de formes rencontrées sont présentées dans le tableau 6.
Tableau 6. Termes-valises en sciences de l’Information : Structures et formes rencontrées
Cette évolution s’accompagne d’une nette augmentation de la fréquence des abréviations, une catégorie très large rassemblant ici les acronymes et autres « alphabétismes6 » (Algeo 1991 : 11). Parmi les trois catégories sémantiques que nous avons pu identifier (« concepts et techniques », « noms d’institutions » et « noms de pays »), la catégorie « concepts et techniques » est celle qui rassemble des termes dont les plus fréquents aujourd’hui sont IR (« Information Retrieval »), XML (« Extensible Markup Language ») et KM (« Knowledge Management »). Il faut toutefois noter que la forte augmentation du nombre d’occurrences, à partir de la deuxième décennie (cf. figure 2), ne garantit pas la survie des termes pour autant.
Figure 2. Évolution de la fréquence des acronymes de 1945 à 2015.
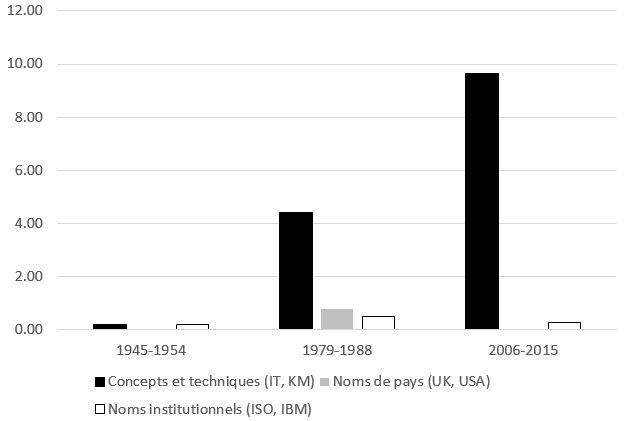
Le maintien des abréviations d’une décennie à l’autre est un phénomène plutôt rare, à l’échelle de quelques cas tels que ISBN (« International Standard Book Number »), IT (« Information Technology ») ou encore ISO (« International Organization for Standardization »). La plupart des cas observés sont en réalité des hapax qui, ici, sont des abréviations qui résultent d’une convention ponctuelle dans la communauté des spécialistes.
4.3. Évolutions sémantiques : Nouvelles définitions et nouvelles métaphores
Notre étude comparative de trois périodes clés de l’histoire des sciences de l’information, consolidée par une étude épistémologique, fondée sur le dictionnaire spécialisé Harrod’s Librian’s Glossary, nous a permis de dégager trois grandes phases du développement sémantique du domaine. La première phase, datant de la fin des années 1970 concerne le développement du concept d’Information. C’est en effet à cette époque que l’un des pionniers du domaine, Jason Farradane, ancre le concept dans champ de la communication humaine et le rend indissociable de la notion de « record », le document structuré, portant la trace, écrite ou orale, d’une activité humaine (Farradane 1979). À cette première phase de conceptualisation succède une deuxième phase d’évolution épistémologique au cours de laquelle le concept d’Information devient véritablement opérationnel, même si le problème de la définition du concept reste toujours aussi prégnant. Les articles du glossaire Harrod en sont l’illustration. Entre 1977 et 2005, la définition de l’Information passe d’une conception philosophique pour ainsi dire à une définition plus technique, centrée sur le traitement des données.
Information :L’ingrédient essentiel à tout système de contrôle(Harrod 1977 : 418)
Information :Un assemblage de données sous forme intelligible et pouvant être communiquée. Il inclut divers éléments allant du Contenu, quelle que soit la structure véhiculant ces contenus (écrite ou imprimée, stockée dans des bases de données électroniques, données recueillies sur Internet, etc.), aux connaissances personnelles que possèdent les membres d’une organisation. (Prytherch 2016 : 349)7
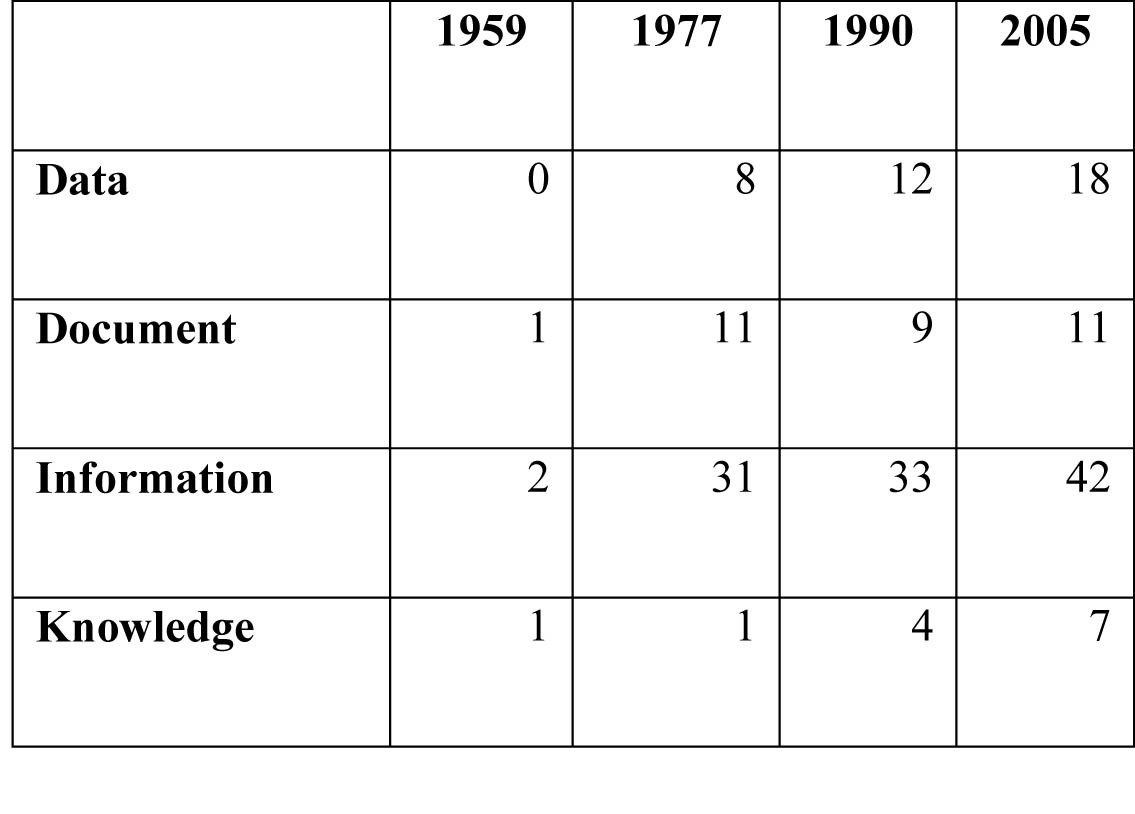
La structuration du concept conduit alors à une troisième phase de fort développement du champ d’application de l’Information, comme en témoigne l’augmentation relativement fulgurante du nombre d’entrées du dictionnaire à base du terme (2 entrées en 1962, 34 en 1990 et 51 en 2005). Dans la période la plus récente, le concept d’Information porte sur des personnes (« information broker », « information consultant »), des activités (« information industry », « information audit », « information engineering », « information mapping »), et des espaces plus ou moins institutionnalisés, dédiés à l’information (« information centre », « information superhighway », « information department »). Le concept sert également de point d’appui à de nouvelles catégories centrales à la société de l’information tels que « information literacy », « information management » ou encore « information retrieval ». L’observation de ce phénomène de dictionnarisation (Van der Yeught 2012) du terme « information » est similaire à celui que connaissent d’autres termes centraux tels que « data », « document » et, plus récemment « knowledge » (cf. tableau 7). À mesure qu’ils entrent dans le dictionnaire et qu’ils s’y développent à travers la multiplication du nombre d’entrées, leur définition s’ajuste aux mutations technologiques pour devenir de nouveaux termes à part entière. La définition de ces termes dans le Harrod’s Glossary, tout comme dans les encyclopédies auxquelles nous avons eu accès, est en effet indissociable des problématiques techniques liées à la recherche d’information et à l’optimisation des systèmes dans lesquels cette information se trouve partagée. Par exemple, le terme « knowledge », et sa mise en œuvre organisationnelle, le « knowledge management », sont définis comme l’optimisation des connaissances de telle sorte qu’elles rendent potentiellement service aux institutions (une entreprise ou une grande organisation) qui les mobilisent (Feather et Sturges 2003).
Tableau 7. Processus de dictionnarisation de quelques termes centraux en sciences de l’information : Comparaison de nombre d’entrées dans quatre éditions du Harrod’s Glossary
Parallèlement, l’expansion sémantique et conceptuelle du domaine produit les nouvelles métaphores de l’Information en réseau. Cette expansion apparaît dans le corpus de manière tout à fait saillante dès la deuxième décennie étudiée, époque à partir de laquelle le domaine de l’Information bénéficie des progrès de l’informatique et de ses modèles mathématiques. Il s’ensuit que la plupart des métaphores constatées empruntent à ces deux domaines, même si certaines établissent de nouvelles correspondances avec des objets ou des actions concrètes. L’observation du corpus montre que les métaphores en sciences de l’Information remplissent trois grandes fonctions représentatives. La première consiste à représenter l’information dans sa structure et son étendue à travers des termes métaphoriques tels que « cloud », « conceptual map », « tree structure », « world wide web », « data warehouses », « knowledge pyramids » ou encore « data streams ». La deuxième catégorie représente l’information dans son immensité à travers des termes tels que « digital realm », « big data » ou « crowd sourcing ». Enfin, la troisième catégorie représente les processus de recherche d’information, qu’il s’agisse de « data mining », « pattern mining », « nearest-neighbour searching ». Ces métaphores témoignent clairement du bouleversement conceptuel qu’a connu l’Information entre 1945 à 2016 en passant d’un état solide et matériel (le livre, le document en format papier) à l’état fluide et immatériel (la donnée et ses multiples bases). À ce bouleversement correspond des nouvelles logiques de recherche d’information qui, sur la période étudiée, passent de la logique claire de la classification hiérarchique telle que la classification de Dewey à la logique floue et approximative (« fuzzy logic », « nearest-neighbour ») de la recherche d’information par algorithmes.
4.4. Évolutions phraséologiques
L’étude de l’évolution phraséologique du domaine porte ici sur quatre termes transversaux aux décennies étudiées (« data », « document », « information » et « knowledge ») dont nous avons exploré l’environnement phraséologique immédiat, c’est-à-dire dans un co-texte réduit à l’échelle de quelques mots à droite comme à gauche. Dans cette partie de l’étude, nous souhaitons mettre en évidence l’expansion phraséologique de termes certes traditionnels dans le domaine mais qui, progressivement, se trouvent associés à de nouvelles problématiques, voire de nouveaux sous-domaines. Cette expansion apparaît tout d’abord de manière générale lorsque nous comparons les indices de variété lexicale (ratio type/token) des groupes nominaux comprenant ces termes (cf. figure 3).
Figure 3. Comparaison diachronique de la variété lexicale des clusters de trois termes centraux en sciences de l’Information (ratio type/token)
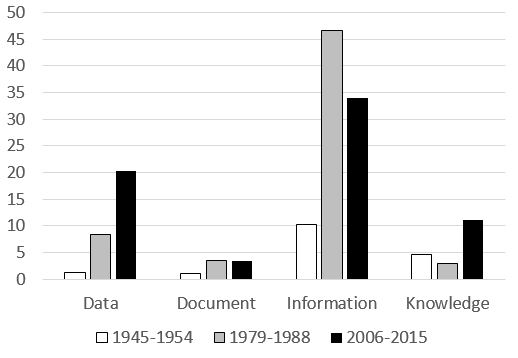
La figure 4 montre l’augmentation sensible du nombre de colocats du mot « data ». Alors qu’entre 1945 et 1954, le nombre d’associations de ce terme se limite à quelques notions (« specialist », « empirical », « numerical » et « scattered »), ce nombre augmente sensiblement pour former dans la dernière décennie une phraséologie radicalement différente. L’évolution phraséologique témoigne d’une montée en puissance d’un terme progressivement associé à de nouvelles techniques et de nouveaux langages (« data processing », « data-driven », « XML data ») et de nouveaux types (« raw data », « web data », « authorship data », « spatial data », « RDF data »).
Figure 4. Évolution phraséologique du terme « data » entre 1945 et 2015.

Comme les autres cas étudiés le montrent, cette montée en puissance se présente de manière tout à fait spectaculaire avec le terme « information » dont la variété lexicale atteint son apogée entre 1979 et 1988 pour ensuite diminuer dans la dernière décennie, époque au cours de laquelle le terme « knowledge », lui, gagne du terrain à travers le développement du « knowledge management » (la gestion des connaissances), considéré aujourd’hui comme un sous-domaine à part entière des sciences de l’Information.
5. Conclusion
Cet article avait pour objectif de documenter l’évolution terminologique du domaine des sciences de l’information à travers le prisme de deux revues phare du domaine, tout en présentant les sciences de l’Information comme un nouveau domaine spécialisé observable du point de vue de l’anglistique de spécialité.
Il faut tout d’abord nuancer la portée d’une telle recherche qui repose sur un corpus relativement restreint et circonscrit à la dimension scientifique de l’Information. Ici, l’évolution terminologique est envisagée dans le cadre précis du discours scientifique et il conviendrait d’observer le phénomène dans un cadre plus large, incluant le vaste champ des métiers de l’Information (information managers, archivistes, documentalistes en institution publique ou privée, etc.) et un corpus de langue plus générale afin de voir si certains termes, à l’instar de data et d’algorithm, obtiennent déjà une forme de consécration sociale, pour reprendre l’expression de Cusin-Berche (1998).
Sur le plan méthodologique, nous avons montré que l’étude diachronique d’un domaine spécialisé s’avère très efficace lorsque celle-ci se fonde directement sur les grandes phases de son développement scientifique. L’approche par mots-clés du corpus a, par exemple, permis d’identifier les premières tendances évolutives, qui tendances ont ensuite été approfondies grâce à une approche qualitative. Cette dernière, fondée sur la comparaison des définitions et l’étude de l’histoire du domaine nous a par ailleurs permis de limiter le biais lié à la petite taille du corpus et à l’échelle, tout aussi réduite, de la diachronie. Il convient toutefois d’ajouter que nous n’avons pas traité la quantité relativement importante d’hapax car nous souhaitions nous livrer à une première caractérisation de l’évolution du domaine à travers les termes les plus saillants d’un point de vue statistique. Comme Resche (2013) l’a déjà observé dans ses travaux sur l’économie, certains termes, en dépit de leur faible fréquence dans un corpus donné, et parce qu’ils peuvent relever de sujets fondamentaux ou dénoter de courants de pensée, peuvent potentiellement contribuer au compte rendu d’une langue de spécialité.
L’évolution de l’Information, et la prolifération de termes qui l’accompagne, pourrait jeter un doute sur la cohérence d’un domaine relativement émergent et dont les préoccupations aujourd’hui ont déjà bien changé depuis les débats scientifiques liés à la classification des documents imprimés dans les années 1940. Cependant, notre observation montre bien qu’à l’échelle synchronique de chaque période étudiée, l’Information présente une homogénéité terminologique relativement forte, essentiellement tournée vers les techniques de classification. S’il est vrai que ces techniques ont radicalement changé depuis 1945, notre étude met en évidence qu’elles s’inscrivent dans une forme d’intentionnalité collective très générale, qui traverse les époques et que les spécialistes de ce domaine appellent « l’organisation des connaissances ». Cette cohérence dans l’évolution, ajoutée aux éléments que nous avons abordés dans cet article, nous mènent donc à la conclusion que l’Information formerait un domaine spécialisé, que des études ultérieures pourront explorer et élargir à d’autres textes et contextes.
Remerciements
Nous remercions Christian Cote, Maître de conférences HDR en sciences de l’information à l’université de Lyon, pour ses conseils et ses suggestions lors de la rédaction de cet article.